Before we delve deeper into RabbitMQ concepts, let’s set up this app on our computer. In my opinion, the best approach is to utilize Docker. I prefer to avoid writing lengthy commands in the terminal, so we will opt for a Docker Compose file. Create folder project folder and create this file:
# ./docker-compose.yml
version: "3.7"
services:
rabbitmq:
image: rabbitmq:3-management-alpine
container_name: rabbitmq_learn
ports:
- 5672:5672
- 15672:15672
Notice that I used management-alpine version that include web management console
in it, available in port 15672. And port 5672 is the port where we can connect
to the system via AMQP (Advanced Message
Queuing Protocol).
Buy the way - RabbitMQ supports other protocols like Streaming Text Oriented
Messaging Protocol (STOPM), Message, Queue Telemtry Transport (MQTT) and others
Start the app by running:
$ docker compose up -d
Let this app up and running in the background while you can continue reading.
AMQP Queues
Queues are a collection of entities maintained in a sequence. Sequence ( queue ) can by modified by adding entities to the beginnign or to the end, removing from the beginning or from the end of the queue.
Queues-metrics
Queue size - number of messages in the queue,
Queue age - age of the oldest message in the queue.
If you have 1 million messages and the oldest one is 5 seconds - it’s okay, and your system handle queue easely, bacause it means that your system handle 200 000 messages per second. But if your queue have 10 messages and the oldest one is 5 minutes - do some thing cuz’ it bearely handle any messages in the queue.
Use cases
Queue architecture offers several advantages for building modular systems that use different languages and technologies:
- Modularity: Queue-based systems enable you to build modular, decoupled components that can be written in different languages and technologies. This promotes flexibility in designing and evolving your system.
- Performance Estimation: You can estimate the performance of your system more effectively because each component communicates through queues, making it easier to measure and optimize individual parts.
- Fault Tolerance: Queue systems enhance fault tolerance. If one component fails or experiences issues, the messages can be stored in the queue, ensuring that they are not lost. This resilience improves the overall reliability of your system.
- Horizontal Scaling: Queue architectures support horizontal scaling by allowing you to add more instances of components that consume messages from queues. This makes it easier to handle increasing workloads and traffic.
- Autoscaling: With the right setup and monitoring, you can implement autoscaling strategies to automatically adjust the number of instances based on workload, ensuring efficient resource utilization and responsiveness.
- Handling Inbound Traffic: Queue systems can absorb spikes in inbound traffic. Messages are queued, preventing overload, and allowing components to process them at their own pace. This helps to smooth out traffic fluctuations.
- Buffering Outbound Data: Queue systems can also be used to buffer outbound data. Instead of sending data directly to external services, you can queue it and then have dedicated components responsible for managing the delivery. This helps ensure data reliability and availability.
Overall, queue-based architectures provide a powerful foundation for building distributed and scalable systems that can handle diverse workloads and maintain high levels of reliability and performance.
AMQP Message
RabbitMQ contains this parts:
- header - metadata, key/value pairs - defined by AMQP specificatoin
- properties - metadata, key/value pairs - Application specific information holder
- body - payload is sequance of bytes ( byte[] )
AMQP Connections and Channels
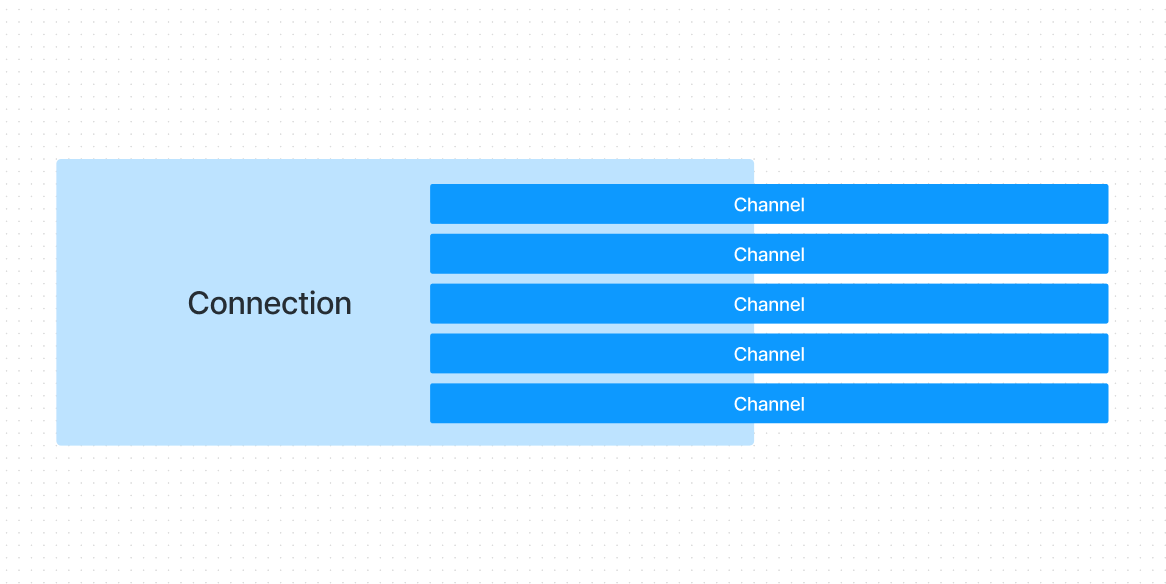
Inside connections, you can open multiple channels. A connection represents a TCP/IP connection between the client and the broker, while a channel is a virtual connection within the physical TCP/IP connection.
The reason for using multiple channels inside a single connection instead of opening multiple connections is efficiency. Establishing a TCP/IP connection can take some time, and having multiple connections for each task or operation can slow down communication considerably.
By using channels within an already established connection, you can achieve faster communication because you avoid the overhead of repeatedly establishing new TCP/IP connections. This approach is more efficient and helps optimize resource usage. For more detailed information, you can refer to the official documentation.
Queuing model
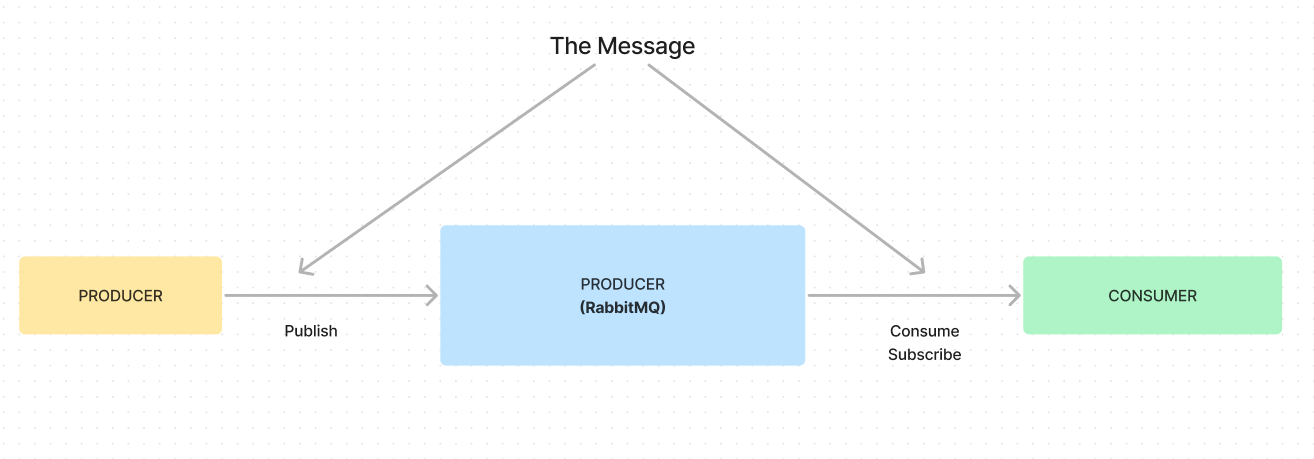
The producer produces a message, which is then handled by the RabbitMQ broker and subsequently consumed by a consumer. Once the message is successfully consumed, it is no longer available in RabbitMQ. In essence, RabbitMQ does not store consumed messages, as it primarily functions as a message broker responsible for routing and delivering messages to consumers.
RabbitMQ Web Admin
Okay. Our app is definitly runnning and you can check this by enter in web admin
by url: http://localhost:15672. Default credentials
are guest:guest. And you will see this page:
About users and authorizations you can read official documentation
I will not writing details about web interface because it’s not the topic of this article. But this is the place where you can practice.
Core concepts
- Producer - emits messages to exchange.
- Consumer - receives messages from the queue.
- Queue - Keeps/Stores messages ( In RabbitMQ producer never published directly in the queue. It Has to use exchange ).
- Exchange - is bound with queue by
binding key. It dicides in which queue message should be placed. It comparerouting keywithbinding key.
This is communication chart:
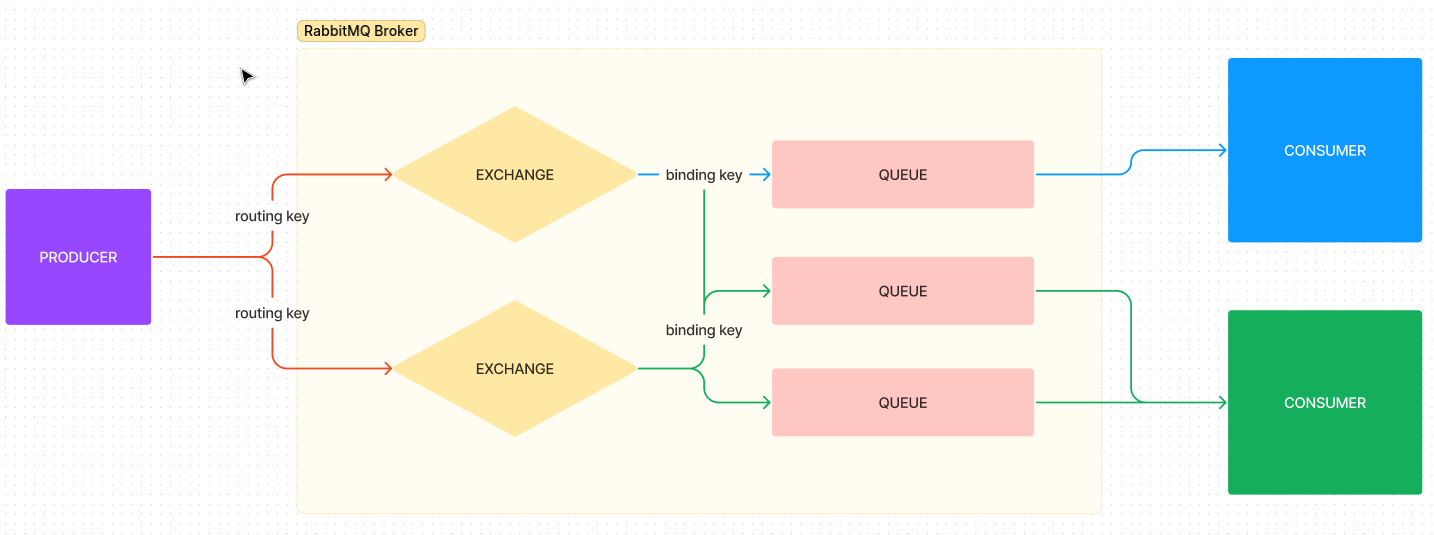
When a producer sends a message with a routing-key of “foo” the routing key can
be thought of as a string value, similar to categories or tags in blogs. The
exchange receives the message and compares it with existing bindings, known as
binding-keys. If there is a queue with the same binding-key, the message is
persisted in the bound queue. RabbitMQ then delivers the message to the consumer.
However, if there are no binding keys that match the given routing key, the
publisher receives an error.
There are many exchange types:
- nameless - default
- fanout
- direct
- topic
- headers
In
Exchangestab in web admin panel you can find predefined Rabbitmq exchanges. You can’t modify them.
nameless
The nameless exchange (default) compares the routing key with the queue name. This allows for sending messages directly to the queue (technically, it sends messages through the exchange into the queue, but it feels like direct messaging).
fanout
It routes all received messages to all queues that are bound to it. Ignores routing key. It’s like a fan that spread messages all around to the all queues.
direct
It send message to the queue that match routing-key. Nameless exchage is the
direct exchange
topic
It routes a received message to queues where binding key defined by a pattern. For
example binding key *.log.error routing key application1.log.error. If any
binding key does not match routing key - producer will receive the error.
headers
It’s simular the topic exchange but it compares against any or all message
headers ( header x-match determinees the behavior ).
Queue concepts
Located on a single node, where it was declared and referenced by a unique name, each queue corresponds to one Erlang process. A queue is essentially an ordered collection of messages that are handled according to the FIFO principle, except for prioritized queues. Internal queues are prefixed by amq.
Main Queue Properties
QUEUE_NAME- human readable namedurable: bool- survived brocker restartexclusive: bool- used for only one connection and will autodelete when connection closesautoDelete: bool- autodelete queue when all consumers disconectedclassic or quorum- increases availabilitypriority- queues are FIFO by default, but you can change it by using this propertyExpiration time (TTL)- remove not consumed messages after some time.
All properties listed in official documentation
Thread about naming convention as best practices to not mess around with names of exchanges, routing keys, queues etc…
Conclusions
RabbitMQ is indeed designed to be flexible, and while its configuration can be intricate, focusing on the right architectural principles can simplify its use. Here are some key steps to consider when designing a system based on RabbitMQ:
- Define Your Consumers and Providers: Clearly identify the components that will produce messages (providers) and those that will consume them (consumers). This step is fundamental to understanding your messaging needs.
- Group by Purpose: Group consumers and providers based on their roles or purposes. For example, loggers and metric services might have distinct responsibilities from product and back-office services. Avoid mixing these different types of services on the same queues to maintain clarity and separation of concerns.
- Understand Priorities and Load: Evaluate the priority and anticipated load of your queues. Some messages may require faster processing or have higher importance than others. Consider setting up different queues with appropriate priorities to handle various message types effectively.
- Basic Configuration: Once you have a clear architectural plan in place, configuring RabbitMQ becomes more straightforward. You can adjust queue properties, message routing rules, and other settings to align with your design.
- Monitoring and Scaling: Implement monitoring and scaling strategies to ensure that your RabbitMQ-based system performs optimally. You can use tools like RabbitMQ management plugins or third-party monitoring solutions to keep an eye on message queues, consumers, and system health.
By following these steps, you can design a RabbitMQ-based architecture that aligns with your application’s needs and efficiently handles messaging between components. It simplifies the configuration process and ensures your messaging infrastructure operates smoothly.
In the next posts, I will continue to explore RabbitMQ with a more practical approach.
Used information
- Basicaly this post is my conspect of Udemy course. If you want to know more about RabbitMQ - buy this greate cource.
- Official documentation